Problem and Opportunity
The company Adentra is a distributor of architectural products, including hardwood and lumber. This company has grown through acquisitions, buying competitors who sell similar or the same products. There is no industry standard for defining architectural products, and so each of the acquired companies has built its own product catalogues independently, with similar but distinct attributes and values.
Adentra’s e-commerce platform requires a standard product catalogue format without duplicate products. Today, a group of senior business “operators” are manually reviewing the acquired product catalogues and deciding the common standard attribute values. There are thousands of items to review, and the review task is slow and labour-intensive.
This project aims to build a PHP web application that integrates Adentra’s product catalogue database to read items from the acquired catalogues and “normalizes” them to a set of standard attributes. This application will automate a laborious and time-consuming task.
Initially, the web application will use its own local database for normalization – this approach limits any security or production risks that the application could introduce.
High-level System Design
The Adentra web app will be built using the Model-View-Controller (MVC) design pattern, in which database logic (model), business logic (controller), and user interface (view) code are separated and encapsulated. In this pattern, the database is accessed only by the controllers, not by the user interface.
Figure 1: System Component Diagram below shows the MVC pattern.
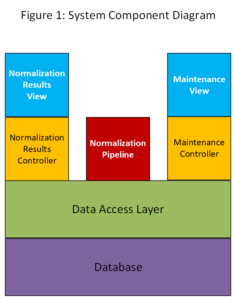
From the bottom up:
- Database: The database used in this project is the open-source MariaDB, a SQL database.
- Data Access Layer: This layer consists of Data Access Objects (DAOs) that contain the necessary SQL statements to create, retrieve, update, and delete product items and their attributes. If another database is to be used, for example, Adentra’s production data lake, then the DAOs in this layer would need to be modified, but the controller and view (UI) code above the data access layer would remain unchanged.
- Normalization Results Controller, Normalization Pipeline, Maintenance Controller: These controllers contain business logic and are invoked by the web page UIs or views. These controllers will invoke DAO functions when they need to access the database.
- Normalization Results View, Maintenance View: This layer contains the user-facing web pages rendered in the browser. Any user input is handled by the view’s controller.
Given this is a preliminary high-level design, we will add more controllers and views as new requirements are discovered.
There will be no database stored procedures used in the development of the web application – all business logic will be in the controller layer. This design decision increases the portability of the DAOs to other database technologies.
Software Development Model
A software development model should maximize the probability of the project’s success by minimizing risk, regularly engaging Adentra’s subject matter experts and stakeholders, and providing regular visible progress. An Agile or iterative development model will be used to uncover risks earlier in the development process and to allow Adentra’s stakeholders to provide feedback before the project is completed. Adentra’s IT staff will eventually extend this application, and so their regular involvement is necessary.
The project’s sprints are sequenced to address the main technical risk: building an attribute normalization algorithm with low accuracy. The sprints are 2 weeks long. The “Definition of Done” for a development task includes unit tests (using PHPUnit) and static code analysis with the SonarQube Community Edition. Unit test coverage should be at least 80% of the code.
Proposed Sprints
Below is a proposed schedule and work breakdown for this project. This schedule is currently tentative because we are not performing all requirements analysis and design upfront, as in a “waterfall” development model.
Sprint 1: December 15th→December 26th:
- Set up a PHP development environment and create a Git repository for this project.
- Create a database schema to support standard attributes and values, as well as a sample of “un-normalized” items and their attributes. Adentra has provided Excel spreadsheets for standard attributes for the lumber category, a sample of normalized Poplar lumber items, and a set of 188 un-normalized Poplar lumber items.
- Create a Python program to populate the database using data from Adentra’s spreadsheets.
Sprint 2: January 5th→January 16th
- Create a “multi-stage normalization pipeline.” Simple text matching will be too “brittle” for dimension matching, e.g., matching lumber thickness, width, and length. This pipeline will need the following stages:
- Text normalization – conversion to lower text, stripping redundant whitespace.
- Dimension extraction – use regular expressions and pattern matching to extract thickness, width, and length from un-normalized attributes.
- Canonical unit conversion – convert to a common measurement, e.g., inches, for comparison in the next stage.
- Standard dimension matching – match against the standard attribute set.
- Calculate the confidence level of the attribute match.
Sprint 3: January 19th to 30th
- Create a review web page for normalized items. The operator uses this page to interactively review the normalization results.
Sprint 4: February 2nd→February13th
- Maintenance & Configuration Pages: Some initial configuration for the normalization pipeline may have been performed using the database tool phpMyAdmin, and this configuration needs to be performed in the web app.